
Model capturing mechanisms in PyTorch
As a natively eager DL framework, PyTorch follows the define-by-run scheme to construct the computation graph only in the 1.x era. Entering 2.x era, PyTorch gradually moves to export models (dynamic computation graphs) into static format for efficient execution. Interestingly, TensorFlow reversely adopts the dynamic eager mode since its 2.x release, where we can observe these two counterparts move towards each other.
Regarding recent PyTorch 2.7 release, there are 4 primary approaches to export a model written in PyTorch into static graph:
Besides, some echosystems originated from PyTorch like AOTInductor and ExecuTorch also provide the interface to dump models into compiled artifacts.
During exporting, the instruction sequences needs to be expressed in a abstract representation, with flowing tensors/parameters being recorded as well.
In current implementation, fx.symbolic_trace and Dynamo share torch.fx.Graph as their IR, while the other 2 interfaces in torch.jit adopt a dedicated format named TorchScript to express the graph.
In this article, we mainly focus on the frontend of model exporting, i.e., the process of converting DNN computations written in PyTorch APIs into framework-agnostic format. For clarity, we just overlook the backend stage (e.g., TorchInductor) which further transforms the exposed IR by lowering/optimizing with hardware/graph-level information. Furthermore, it's better for the audience to have a basic concept of Python/CPython internals to understand the underlying working mechanisms, especially for Dynamo.
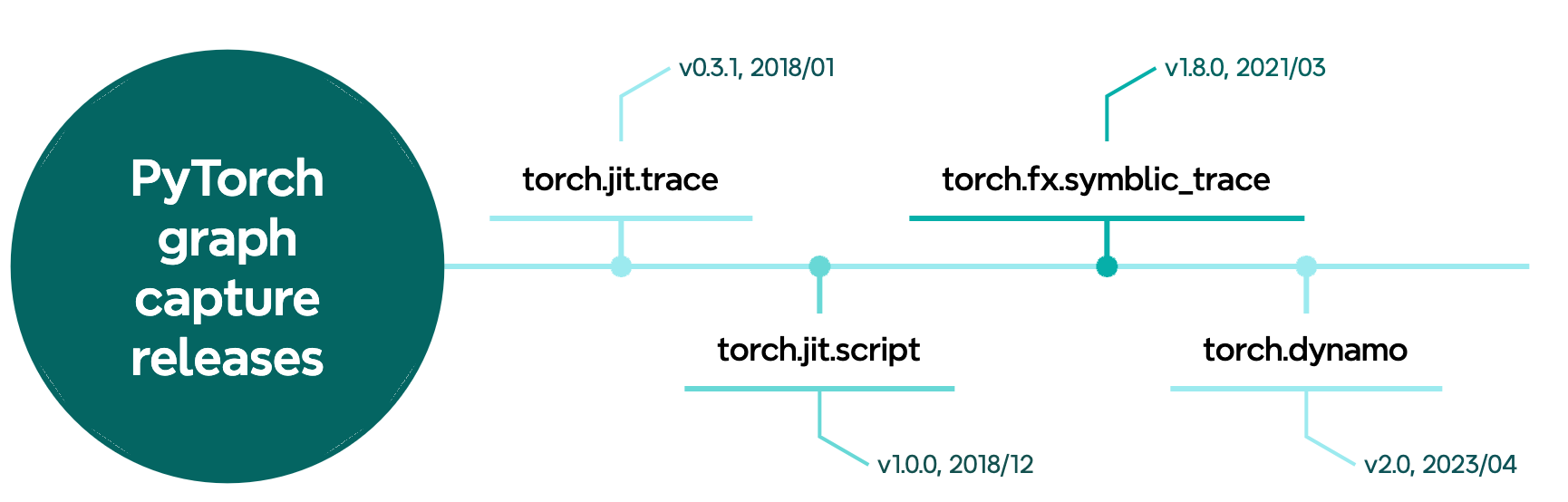
Release timeline for graph capture components in PyTorch
1. Before PyTorch 2.0: torch.jit
In the age of PyTorch 1.x, model tracing is mainly achieved via torch.jit APIs.
However, since the 2.x release, the TorchScript module now are under the maintainance mode1.
So personally I don't want to spend too much time on it, and we just skip them as for now.
Maybe someday I will come back and fill this part.
2. torch.fx.symbolic_trace
torch.fx.symbolic_trace2 (we abbreviate it by fst in the following text) is a static tracing approach to record the tensor operations in a root torch.nn.Module.
It does so by replacing the substantial tensor objects and operations by proxy objects, and patch the getattr and __call__ methods for PyTorch modules.
After finishing tracing, it produces a static torch.fx.Graph.
2.1 How methods patched?
Relax!
Python is a dynamic programming language allowing users to overwrite any object attributes on-the-fly.
In fst, PyTorch patches two important dunders for torch.nn.Module type:
__getattr____call__
It accomplishes method patching with:
setattr(torch.nn.Module, __getattr__, patched_getattr_fn)
setattr(torch.nn.Module, __call__, patched_call_fn)
For torch.nn.Module, the __call__ dunder will further invoke its forward method.
With these two patches, fst could conduct extra operations for a module written in PyTorch.
For example, for a common model structures written in PyTorch APIs:
class SimpleResNetBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv1 = nn.Conv2d(
in_channels, out_channels, kernel_size=3, stride=stride, padding=1
)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(
out_channels, out_channels, kernel_size=3, stride=1, padding=1
)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = None
if stride != 1 or in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels),
)
def forward(self, x):
identity = x
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
if self.downsample:
identity = self.downsample(x)
out += identity
return self.relu(out)
class ExampleModel(nn.Module):
def __init__(self):
super().__init__()
self.stem = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.MaxPool2d(2),
)
self.block1 = SimpleResNetBlock(16, 32, stride=2)
self.block2 = SimpleResNetBlock(32, 64, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(64, 10)
def forward(self, x):
x = self.stem(x)
x = self.block1(x)
x = self.block2(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
In the forward run, patched_getattr_fn will be invoked when accessing a registered component in the model, e.g., self.stem.
Also, patched_call_fn is called when forwarding a module, e.g., self.stem(x).
2.2 Patching torch.nn.Module.__call__
In short, patched_call_fn is responsible for injecting all calls to leaf modules by recursively walking through the code, line-by-line.
In current implementation (2.7.0), given a torch.nn.Module instance m, we say it is a leaf module if:
return (
m.__module__.startswith("torch.nn")
or m.__module__.startswith("torch.ao.nn")
) and not isinstance(m, torch.nn.Sequential)
That says, fst will not trace into atomic operations like torch.nn.Conv2d.
Instead, it just records them and emits call_module nodes in the output graph.
The leaf modules can be easily converted into framework agnostic format, e.g., ONNX.
If the injected module m being called is not a leaf module, fst will trace through m by calling the original unpatched forward method, which is dumped in a global variable named _orig_module_call before patching.
In this case, fst enters the scope of m.forward, and recursively emulates every single line in the code.
2.3 Patching torch.nn.Module.__getattr__
Meanwhile, fst patches torch.nn.Module.__getattr__ to avoid direct accessing towards torch.nn.Parameters for the model being traced.
It rather creates a Proxy object p used to represent the substential parameter, and stores it in a global cache so that p can be returned from cache immediately for all subsequent accesses.
In practices, patched_getattr_fn mostly returns the real attribute object (e.g., torch.nn.Module or other model-specific attributes) as we rarely touch the model parameters when crafting the forward function (since in most cases we rely on the autograd mechanism in PyTorch to update model parameters).
2.4 When proxy emitted?
In the following scenarios, fst will generate a fx.Proxy object representing a symbol (that's why this mechanism names torch.fx.symbolic_trace):
- when leaf module is encountered (e.g.,
nn.Conv2d), fst emits acall_moduleproxy and inserts it into the output graph - when a function is invoked with any of its parameters is a proxy, e.g.,
torch.flatten(x)called above, asxis a proxy symbolic flowing across layers
Note that for built-in tensor operators like +, fst automatically replace the operator with the corresponding function call (e.g., operator.add).
2.5 An example
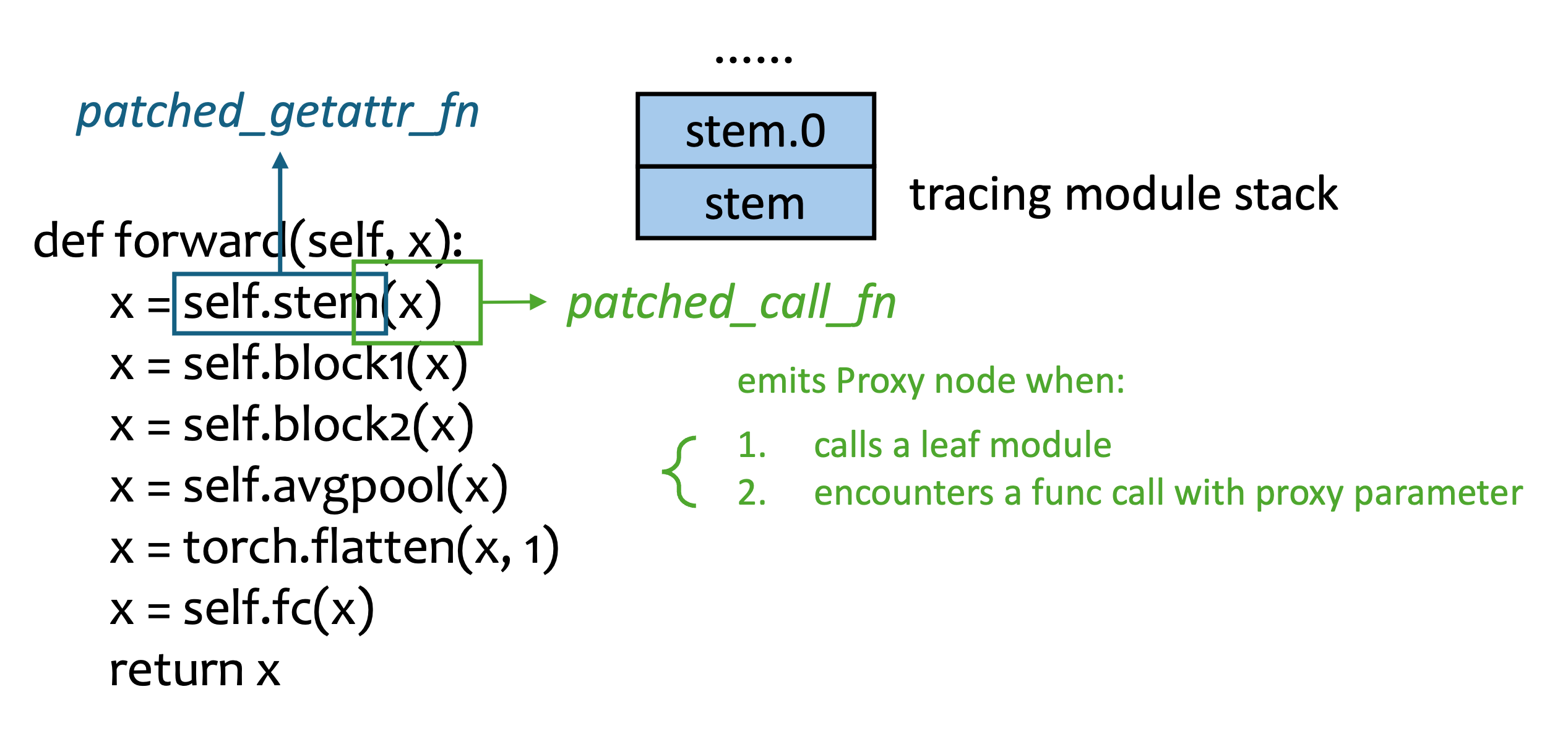
An example demonstrating how fst traces torch.nn.Module
The figure above demonstrates how fst symbolically traces a torch.nn.Module execution.
In the forward function, we feed the input tensor into sub-components (registered in __init__) by accessing attributes, where the patched_getattr_fn is invoked as a trampoline to intercept torch.nn.Parameter accessing.
Normally, the original sub-module (typed in torch.nn.Module as well) is returned, and we transform the input tensor by calling its forward method, at which patched_call_fn is thus called.
The patched_call_fn emits Proxy nodes into the output graph whenever necessary, and maintains a global stack (tracing module stack in the figure) to record the frames currently being traced, which can be used to emulate the control flow like loop or recursive calling.
Ultimately, fst travals through the root module (and all its sub-modules encountered in forward), and generates the leaf module/function sequence in the torch.fx.Graph format.
The aforementioned ExampleModel model outputs a symbolic trace like this:
opcode name target args kwargs
------------- ------------------- ---------------------------------------------------------- --------------------------------- --------
placeholder x x () {}
call_module stem_0 stem.0 (x,) {}
call_module stem_1 stem.1 (stem_0,) {}
call_module stem_2 stem.2 (stem_1,) {}
call_module stem_3 stem.3 (stem_2,) {}
call_module block1_conv1 block1.conv1 (stem_3,) {}
call_module block1_bn1 block1.bn1 (block1_conv1,) {}
call_module block1_relu block1.relu (block1_bn1,) {}
call_module block1_conv2 block1.conv2 (block1_relu,) {}
call_module block1_bn2 block1.bn2 (block1_conv2,) {}
call_module block1_downsample_0 block1.downsample.0 (stem_3,) {}
call_module block1_downsample_1 block1.downsample.1 (block1_downsample_0,) {}
call_function add <built-in function add> (block1_bn2, block1_downsample_1) {}
call_module block1_relu_1 block1.relu (add,) {}
call_module block2_conv1 block2.conv1 (block1_relu_1,) {}
call_module block2_bn1 block2.bn1 (block2_conv1,) {}
call_module block2_relu block2.relu (block2_bn1,) {}
call_module block2_conv2 block2.conv2 (block2_relu,) {}
call_module block2_bn2 block2.bn2 (block2_conv2,) {}
call_module block2_downsample_0 block2.downsample.0 (block1_relu_1,) {}
call_module block2_downsample_1 block2.downsample.1 (block2_downsample_0,) {}
call_function add_1 <built-in function add> (block2_bn2, block2_downsample_1) {}
call_module block2_relu_1 block2.relu (add_1,) {}
call_module avgpool avgpool (block2_relu_1,) {}
call_function flatten <built-in method flatten of type object at 0x153f0eb63220> (avgpool, 1) {}
call_module fc fc (flatten,) {}
output output output (fc,) {}
3. Dynamic tracing: Torch Dynamo
Similar to fst, torch.dynamo is another symbolic tracing approach to capture model structure described in PyTorch APIs.
However, the fundamental difference lays in:
- Dynamo traces at the Python bytecode level, while fst introspects in Python AST level
- Dynamo tracks tensors in graph via
FakeTensorandVariableTracker, while fst harnessestorch.fx.Proxyto emulate the graph execution
Note that Dynamo is the frontend of torch.compile released in PyTorch 2.03, which takes an nn.Module as input, and produces an IR represented in torch.fx.Graph, which is further fed into backends like Triton to optimize.
Technically, there are 3 stages in Dynamo:
- custom Python frame evaluator
- interested variable tracker
- instruction translator
We'll go through the first stage in the following sections, which is most related to model capturing.
3.1 CPython ABC
Before diving into the custom code object and function frame evaluation, we grasp some basic concepts and execution/data model in CPython4.
For the following code:
import torch
import torch.nn.functional as F
def my_matmul(x: torch.Tensor, y: torch.Tensor):
z = F.sigmoid(x)
if torch.any(torch.isnan(z)):
return y
return y * z
print("co_names: ", co.co_names)
print("co_consts: ", co.co_consts)
print("co_varnames: ", co.co_varnames)
print("co_stacksize: ", co.co_stacksize)
The Python code inside my_matmul will be parsed into AST, and then lowered into bytecode5.
You can check the translated bytecode instructions using python3 -m dis bc.py:
Disassembly of <code object my_matmul at 0x1539b95e79f0, file "snippets/bc.py", line 5>:
5 RESUME 0
6 LOAD_GLOBAL 0 (F)
LOAD_ATTR 2 (sigmoid)
PUSH_NULL
LOAD_FAST 0 (x)
CALL 1
STORE_FAST 2 (z)
7 LOAD_GLOBAL 4 (torch)
LOAD_ATTR 6 (any)
PUSH_NULL
LOAD_GLOBAL 4 (torch)
LOAD_ATTR 8 (isnan)
PUSH_NULL
LOAD_FAST 2 (z)
CALL 1
CALL 1
TO_BOOL
POP_JUMP_IF_FALSE 2 (to L1)
8 LOAD_FAST 1 (y)
RETURN_VALUE
9 L1: LOAD_FAST_LOAD_FAST 18 (y, z)
BINARY_OP 5 (*)
RETURN_VALUE
Besides, if you directly run the script, you can get the following results6:
co_names: ('F', 'sigmoid', 'torch', 'any', 'isnan')
co_consts: (None,)
co_varnames: ('x', 'y', 'z')
co_stacksize: 5
As for now, we need to know Python interpreter is actually a stack-based VM (a.k.a, PVM7). When encountering a new function/module, it automatically pushes a frame into the frame stack, and during bytecode execution, the interpreter manipulates the intermediate values via the data stack. Below is the imaginary snapshot of the data stack at each bytecode, you can just treat the bytecode as the ISA in PVM.
| Step | Stack State | Comment |
|---|---|---|
| RESUME | [] | Start |
| LOAD_GLOBAL F | [F] | |
| LOAD_ATTR sigmoid | [F.sigmoid] | |
| PUSH_NULL | [F.sigmoid, NULL] | |
| LOAD_FAST x | [F.sigmoid, NULL, x] | |
| CALL 1 | [z] | z = F.sigmoid(x) |
| STORE_FAST z | [] | z saved |
| LOAD_GLOBAL torch | [torch] | |
| LOAD_ATTR any | [torch.any] | |
| PUSH_NULL | [torch.any, NULL] | |
| LOAD_GLOBAL torch | [torch.any, NULL, torch] | |
| LOAD_ATTR isnan | [torch.any, NULL, torch.isnan] | |
| PUSH_NULL | [torch.any, NULL, torch.isnan, NULL] | |
| LOAD_FAST z | [torch.any, NULL, torch.isnan, NULL, z] | |
| CALL 1 | [torch.any, NULL, isnan_z] | isnan_z = torch.isnan(z) |
| CALL 1 | [any_isnan_z] | any_isnan_z = torch.any(isnan_z) |
| TO_BOOL | [bool_val] | |
| POP_JUMP_IF_FALSE to L1 | — | Branch depending on bool_val |
| LOAD_FAST y | [y] | If NaNs, return y |
| RETURN_VALUE | — | |
| L1: LOAD_FAST_LOAD_FAST | [y, z] | If no NaNs, compute y * z |
| BINARY_OP * | [y * z] | |
| RETURN_VALUE | — | Return result |
An interesting catch: you can notice there is a special instruction above:
LOAD_FAST_LOAD_FAST, which was introduced into CPython since 3.13. It was the result of instruction specialization, see PEP 659 for more details if you're interested.
So the role of Python interpreter is simple and straightforward: it just numbly decodes and interpretes every single bytecode instruction from the compiled Python code, together with the value in the data stack.
Actually, in the implementation, it is an infinite loop with huge huge switch-case written in C, which is located in the _PyEval_EvalFrameDefault function.
And in PEP 523, CPython provides a configurable API for downstream libraries to evaluate the PVM frame with their custom logic. It acts like an indispensible role for Dynamo, a bytecode-level model capturing mechanism by inspecting and manipulating the PVM frame with custom evaluation.
3.2 Dynamo: the bytecode JIT
PEP 523 says you can execute the PVM frame with your custom evaluator, as for current CPython 3.13 stable release, the interface is named _PyInterpreterState_SetEvalFrameFunc.
The PyTorch Dynamo developers leverage this feature to register the JIT frame evaluator into CPython, so that any function (e.g., forward method of an nn.Module) can be evaluated at their will.
So what does the patched frame evaluator do?
The magic lays in dynamo__custom_eval_frame, which is registered as the custom frame evaluator using the aforementioned CPython API.
From high-level perspective, in this function, there is just some "shim" steps to finally get the Python code compiled, including:
- intercept and analyze current frame/code, determine whether there are cached compiled artifacts, and insert and validate guards, if needed
- replace the processed frame (compiled code) when available, and let the default frame evaluator execute the new frame
There are also 3 possible actions regarding each frame to be evaluated:
enum FrameAction {
DEFAULT, // look through the cache, compile if not found
SKIP, // eager
RUN_ONLY, // look through the cache, run eager if not found
};
Based on the program analysis (e.g., if the frame contains some external calls, Dynamo just skips and runs the original frame eagerly) or environment variables, the custom evaluator set the action for each frame.
If the shim decides to custom evaluate the frame, it calls dynamo_call_callback to apply some transformation on the intercepted frame, where the callback is implemented and provided from Python world.
So if you want to have a custom bytecode compiler in PyTorch, you can simply write your own purely in Python (the Dynamo compiler is in _compile).
Actually, I think this is the most successful part of PyTorch, the infra engineers do the dirty things in C/C++, and algorithm engineers/users enjoy the resulting convenience from Python.
If the backend compiler (frame converter/bytecode translator) is able to successfully return a frame, the custom evaluator calls dynamo_eval_custom_code_impl to create a fresh frame from the original one, with some extra steps to copy from local variables from the old to new frame space.
And, the final calling stack may look like this IIUC:

Dynamo workflow. Blue represents Python code while orange means C/C++ dirty codes.
4. Discussion:
And finally, I'd like to propose some discussions about model exporting in PyTorch.
4.1 Tracing mechanisms: emulation vs. frame intercept
Comparing these two mechanisms, we can see fst parses and emulates the model execution by emulating each expression with replaced fx.Proxy.
Instead, Dynamo targets at lower bytecode level.
One obvious advantage of the latter is it can handle the dynamic control flow by introducing compile guards.
For instance, with the following PyTorch code:
def forward(self, x: torch.Tensor) -> torch.Tensor:
if torch.any(x > 0):
return F.sigmoid(x)
else:
return 2 * x
fst fails to handle such computation graph with control flow, as fx.Proxy cannot be evaluated to bool type during tracing8 (this is intuitive, as fx.Proxy is just a symbolic variable containing no runtime information).
However, for Dynamo, it can insert compilation guards when encountering bytecode related to control flow (e.g., POP_JUMP_IF_FALSE, or any other forms).
The guard ensures that any input fed into the compiled unit ought to follow the same execution path.
If not, Dynamo should trigger re-compilation to produce correct artifacts.
4.2 Dynamo still in its early age
Dynamo sounds promising, right?
But if you directly apply it in models with complex logic and many external calls, you will find it's hard to handle enumerous corner error cases.
Besides, there are still large number of unsupported aten APIs, which further hinders the usage of Dynamo or torch.compile in real production environments.
And Dynamo cannot be used when you:
So we can see even Meta still leverages old TorchScript or torch.fx to capture their internal recommendation models9.
4.3 Why LLMs don't need to be exported?
Usually, one exports the PyTorch model after training in order to get rid of runtime overhead due to Python during inference. However, in my observation, current LLM inference does not need the model to be exported, i.e., venders harness inference frameworks like vLLM or SGLang to provide LLM inference services. Does it mean the overhead of Python (e.g. GIL, bytecode dispatch, dynamic type resolution, etc.) is negligible since the computation is dominant regarding LLM application?
5. Takeaways
Some may regard PyTorch as a framework with Python API frontend plus C/C++/CUDA backend.
But Dynamo proves it wrong: PyTorch has been deeply bound to Python runtime, not only due to the usability, but also the extendibility provided by CPython.
It allows developers easily extend the functionality from C/C++ and register back to Python world, like __torch_function__ and AOT Autograd.
The infra engineers should make algorithm counterparts happy, instead of burdening their brains (TensorFlow, do you hear that?).
And PyTorch successully does so.
Footnotes
-
https://github.com/pytorch/pytorch/issues/114755#issuecomment-1832136770 ↩
-
Torch.fx: Practical Program Capture and Transformation for Deep Learning in Python ↩
-
[ASPLOS '24] PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation ↩
-
CPython is the official and most frequently-used implementation of Python interpreter ↩
-
Noneis inco_constsby default ↩ -
https://github.com/python/cpython/blob/main/InternalDocs/interpreter.md ↩
-
https://github.com/pytorch/pytorch/blob/134179474539648ba7dee1317959529fbd0e7f89/torch/fx/proxy.py#L359-L368 ↩